Training or Test errors
- Labeling verification
Verify that no evident and gross labelling errors have been done.
- Look at the FALSE NEGATIVE samples to verify that you have not set the wrong model of a sample, or that you have added a sample in the wrong position.
- Look at the FALSE POSITIVE and TRUE NEGATIVE samples to check if you forgot to add a sample.
If something wrong is founded, correct them, and run the SVL again.
In some cases, a reset may be necessary. To reduce your training time, in Retina or Surface, you can leave only the models with the wrong samples enabled to reset only them.
- Inspect the weights of the samples that are not correctly classified. Evaluate if those samples are "border line" and eventually mark them as Optional.
- See also
- sb_t_sample_classify_mode
- Change of the feature set (Retina, Surface)
- Try to change the Optimization Mode and set it to Medium or Slow. In this case the algorithm itself will execute all the procedures automatically and the feature set will be enlarged.
- Check if the answers you gave in the feature choice menu have to be changed.
- If the problem is not already solved, switch the Optimization Mode in Selected (for expert users). In this case, the user is required to have a good knowledge of the descriptors extracted by the available features and he can manually select the set of features that best fit to the model to be trained.
- See also
- Features
- If training of only a small subset of models does not converge, try disabling all models with positive goodness and run an SVL only on critical models. Before to run the SVL it is necessary to reset it, call sb_svl_reset to reset SVL. The classifier will choose the best recipe that best suits only those specific models.
- Change the network (Deep Cortex, Deep Surface)
Try to change the current deep learning network with a more complex one.
- Number of epochs (Deep Cortex, Deep Surface)
Try to increase the number of epochs in order to have a more exhaustive training. This may improve both SVL metrics and test results. In the case of long trainings, try also to enable save best epoch option.
- Scale Levels (Surface)
With Surface projects try to modify the scale levels configuration.
- Model Size (Retina)
With Retina projects check if the model has too low resolution for the classifier to recognize the object, or, conversely, if the model has too large resolution for which the classifier, having too much information, is confused and cannot recognize the object. See also sb_t_par_model::obj_size .
- Tile factor / Scale (Deep Surface)
In Deep Surface projects try to modify the num tiles (if tiling_mode is equal to SB_TILING_MODE_MANUAL ) or scale (if tiling mode is equal to SB_TILING_MODE_AUTO ). They directly affect the minimum defect size and defect granularity managed by the SVL and detection. Some simple guides line are:
- in case of FALSE NEGATIVE instances on small defects or, more generally, poor defect granularity, try to increase the tile factor or decrease the scale.
- in case of small FALSE POSITIVE instances, try to reduce the value the tile factor or increase the scale.
- Attention
- number of tiles values > (1, 1) increase training and detection time.
-
Scale values equal to (1.0, 1.0) maximize training and detection time.
- Features multiplier (Deep Cortex, Deep Surface)
Try to increase features multiplier parameter. It increases the algorithm complexity going to augment the number of features used to solve the vision task.
- Too much variability
If the object has too great variability, it could happen that the classifier cannot model it correctly. However, if the object is presented in n quite well defined positions then n models could be created instead of a single model. For example, an object that always appears straight and upside down, or occurs in n intervals of angle not superimposed on each other. In some situations it may also be better to set the models as collaborative.
SVL - training
For more information about the SVL see section SVL - training.
Long training times
- Thread number
The number of Thread is a parameter which can considerably improve the training times. - See also
- Parallel computing
- Device (Deep Cortex, Deep Surface)
Set type of SVL device to GPU NVIDIA, rather than CPU, may drastically decrease training time. If a GPU device is already used, install a more performing GPU on the machine. - See also
- Device management
- Decrease ROI area (Retina, Surface)
- RETINA: if the training dataset contains many images, we suggest training the classifier with a "clever" incremental approach. If the user wants to improve the training quality (e.g. there are errors on Test images), but the number of used training images is considerable, it is advisable to enlarge the training set with images with a reduced ROI including only areas of the image with errors (FALSE POSITIVE, FALSE NEGATIVE).
- SURFACE: if the images background has low variability, it is advisable to start to reduce ROI area from the beginning. Thus, include in the training set only a limited number of images (2/3) with the ROI extended to the whole surface to be analyzed. In this way, the training is faster because the classifier does not take time to process the section of the image without useful information content.
- Decrease the number of training images
- In Retina or Surface project it is advisable to remove only images in the training set that are not actually used for training. Alternatively move them in the Test set.
- Decrease Goodness Target (Retina, Surface)
Reduce the value of the Goodness Target parameter to an acceptable value. For such training, especially in those where the detection task requires high generalization capability, high goodness values may be not reachable and may cause overfitting on training data with a degradation of the performance. Obviously, it is important to find an acceptable trade-off: a too low goodness value can lead to underfitting.
- Decrease the number of epochs (Deep Cortex, Deep Surface)
Training time is directly proportional to the number of epochs. The amount of epochs necessary to reach the best SVL results depends on project complexity.
- Decrease Tile Factor / increase the Scale (Deep Surface)
Number of tiles parameter extends number of images internally processed by SVL by a factor tile_factor.width * tile_factor.height.
Similarly, when tiling_mode is auto, the closer to (1.0, 1.0) the scale is, the higher will be the number of images internally processed by SVL, especially in case of high resolution images.
These cases obviously lead to a longer training time.
Under and Over fitting
When we apply Machine Learning method to image vision tasks it is not difficult to perfectly fit our training dataset, especially when we give our algorithm many internal parameters (i.e. degrees of freedom) to fit the observations in the training set. But sometimes, when we evaluate such a complex model on new data, it performs very poorly. In other words, the model does not generalize well. This is a phenomenon called overfitting, and it is one of the biggest challenges of Artificial Intelligence. The problem can be summarized in three possible scenarios, which are shown in the following image. On the left the algorithm has too few parameters and it cannot separate the two classes, on the right the model has too many parameters and it exceeds the training data, in the central case the model has a well-balanced complexity and is able to generalize well.
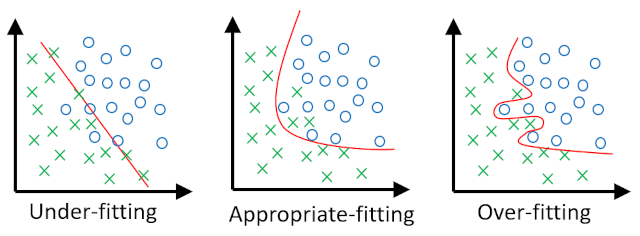
Under and Over fitting
- Overfitting
In machine learning, overfitting is "the production of an analysis that corresponds too closely or exactly to a particular set of data,
and may therefore fail to fit additional data or predict future observations reliably".
In general to reduce overfitting, try to:
- add occurrences of the object so that the training dataset is more representative of the variability of the object itself
In Retina try also to:
- reduce the size of the model
- reduce Goodness Target parameter to an acceptable value
- try to run the SVL with higher search steps, coarse and/or fine, but in detection use lower steps.
- Underfitting
Occurs when a classifier is unable to adequately acquire the underlying structure of the model with the consequent low image segmentation capacity.
In general to reduce underfitting, try to:
- evaluate if same samples are "border line" and eventually mark them as Optional
In Retina try also to:
Test
In order to easily test a training, it is necessary to have a correctly labeled test dataset. In this case the sb_project_detection function will be able to classify the results of the analysis and therefore, counters of both the samples found (TRUE POSITIVE and TRUE NEGATIVE) and the detection errors (FALSE NEGATIVE and FALSE POSITIVE) will be updated. See the image below.
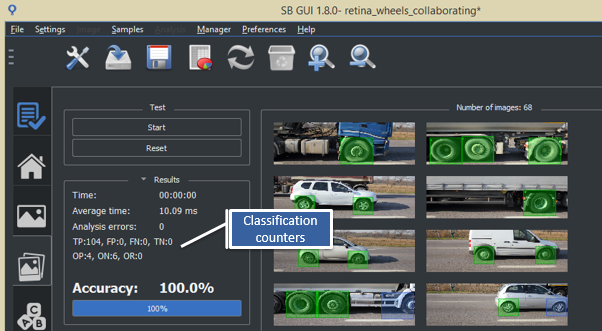
Classification counters
If the images are not labeled, all occurrences will be FALSE POSITIVE and TRUE NEGATIVE., the latter only if sb_t_par_model::num_occurrences parameter is different from 0 (see the image below).
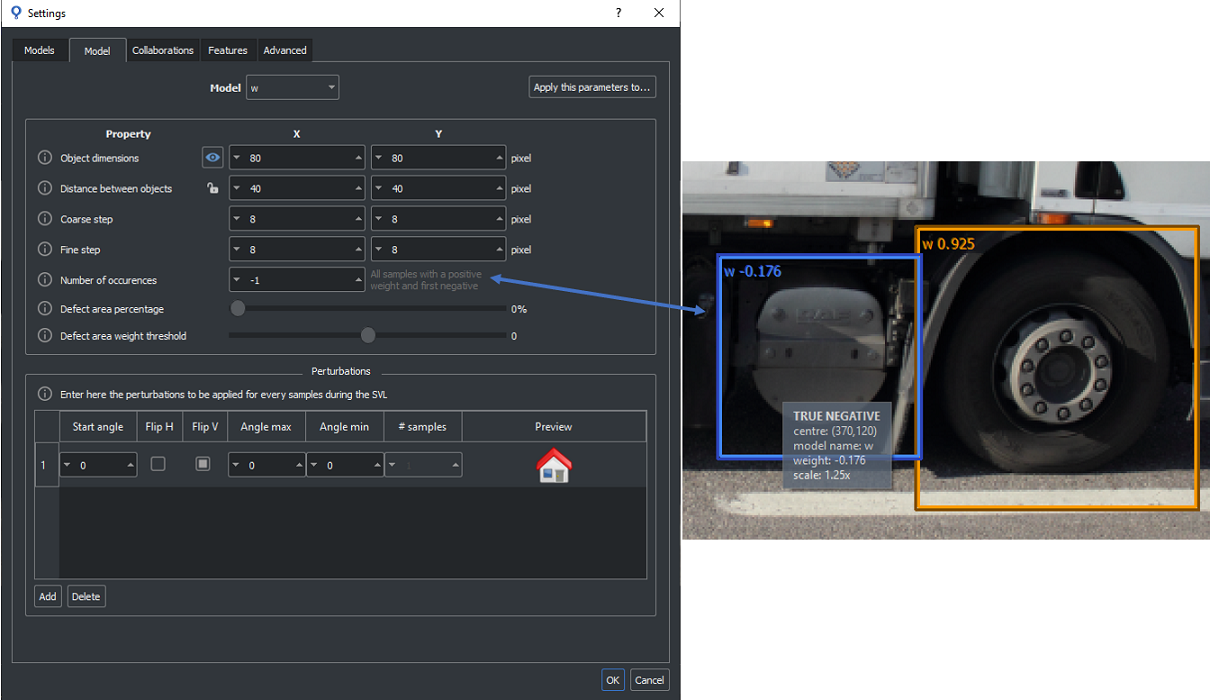
Not labeled image with an FALSE POSITIVE and a TRUE_NEGATIVE sample
Having a properly labeled test dataset allows to check very easily if a change in training is improving or worsening. In fact, if the dataset is labeled, counters provide this information, otherwise it is necessary to check all the images one by one, an operation that could take a long time.
To facilitate the labeling operation, which can be very time-consuming, the SB GUI provides a Labeling Assistant tool. For more details see section Labeling assistant with SB GUI.
Improve separation between TRUE POSITIVE and TRUE NEGATIVE
- Attention
- Retina projects only
Sometimes, even no detection errors occur on test dataset, it is advisable to reinforce the training going to maximize the weight separation between TRUE POSITIVE and TRUE NEGATIVE instances. In order to have available the information about TRUE NEGATIVE samples in the test images it is necessary to set the sb_t_par_model::num_occurrences to a value different from 0.
A first evaluation can be done observing in the SB_GUI the samples weight chart in the section "Test" (see the image below). It graphically shows the weights distribution of the various metric counter in the interval [-1, 1]. The greater the distance between the maximum TRUE NEGATIVE sample and the minimum TRUE POSITIVE sample the more roboust will be the classifier to distinguish positive and negative instances. In case of low distance or when an extreme of the interval is near to 0 is strongly recommended to move the images containing such samples in the training set and to run an incremental SVL.
To facilitate the user to find the samples corresponding to the outmost weights of the interval, it is possible to filter the images by the weight using the special slider in the section Filters.
The operation have to be repeated till the user reaches an acceptable separation (i.e. in most of applications a weights separation > 0.4 with the minimum TRUE POSITIVE and the maximum TRUE NEGATIVE respectively higher than 0.1 and lower than -0.1 is advisable).
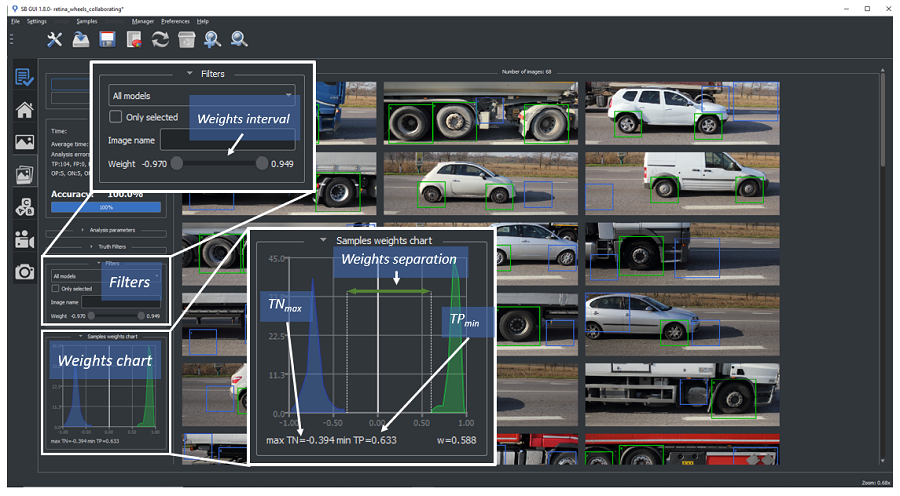
Weights evaluation of test samples
Misclassification errors
- Background Foreground misunderstanding (Retina)
If the background has a low degree of variability in the dataset, may be happen that the classifier learns to describe the model depending by the background information and not by the object one. It is possible to check this situation using the weight map of the sample.
An example of the behaviour may happen when we want to recognize circular objects (like a ring) where the most part of the sample is occupied by the background. In this case, we suggest varying the acquisition background of the training set in order to help the classifier to specialize the training on the ares of the object.
- See also
- sb_t_sample_weights_image
- Collaborations
Check if there are models that can be set as collaborative or, conversely, if models, which are not collaborative, have been set up as if they were.
High number of FALSE NEGATIVE samples
- Check all the conditions listed in the section Training or Test errors.
- Incremental SVL
To make the training more robust select among FALSE NEGATIVE those samples with lower weight and run an incremental SVL.
- Increase the sensitivity
to make the classifier more sensitive may cause a decrease of FALSE NEGATIVE numbers, but also an increase of FALSE POSITIVE. - See also
- sb_project_set_sensitivity
- Collaborations
in multi-model projects some couples FALSE NEGATIVE - FALSE POSITIVE may be due to occurrences which are actually detected but assigned to wrong model. In this case, take into account if models may be set as collaborative. Indeed, it is important to state if you want to allow a sample can be associated to more than one model (e.g. for an OCR application, uppercase and lowercase letters requires a different labelling because they have different topology. However, the misclassification between the uppercase and lowercase version of the same letter may be not considered as an error). If this is the case, we suggest running the SVL with an appropriate configuration of the collaborations between the models. - See also
- Collaborations
- Change other parameters
Retina
Surface, Deep Surface
High number of FALSE POSITIVE occurrences
Long elaboration time
A low IoU value
- Attention
- Retina projects only
If a TRUE POSITIVE occurrence has a low IoU value this means that the intersection between the sample and the occurrence is small.
In the SB GUI it is possible to set a threshold in order to generate an alarm if the IoU value is below the threshold. You will find the IoU threshold in Setting->Advanced. Usually a value between 50% and 80% is suggested.
If not expressly desired, a low IoU value can be a symptom of possible problems:
- Labeling is not correct or inaccurate
- Check that no evident and rough labelling errors have been done in the Training set. They may cause inaccurate spatial localization of the test occurrences because the training is corrupted.
- Check that the ground truth sample associated to the occurrence that generates the warning is correctly located on the object.
- Verify that all the ground truth samples have a correct scale and, if it is not the case, modify it. Note that, in order the labelling being correct, the object instance must be entirely included in the more internal bounding box of the Sample details window. Errors like this, are probable when the user uses for labelling the Labeling Assistant utility without a proper control on the suggested labelling. See sb_t_par_model.
- Object minimum distance
Too high a value of object minimum distance can cause the classifier to train itself to find the object inaccurately.
- See also
- sb_t_sample::IoU
Different results in SVL and Test
- Attention
- Retina projects only
It may happen that the test performed on a training image does not give the results obtained by the SVL.
In this section we will explain the possible differences and the reasons.
The main cause of the difference is the different handling of the sb_t_par_model::obj_min_distance parameter of the training and in the test functions.
With these considerations it is possible to understand that the SVL can end without errors but in detection there may be some FALSE NEGATIVE samples. It can happen when there are samples just more distant than the minimum distance but the relative occurrences are instead closer, therefore the one with the lowest weight is eliminated..
Not possible to use GPU for training and detection
- Attention
- Deep Cortex and Deep Surface projects only.
In this section possible solutions are described to face the problem of having a GPU mounted on the machine but not visible from SB deep learning modules. The problem is not directly notified by the SB library, but the user can easily being aware of it in two ways:
In order to solve the problem check if installed GPU is supported by the CUDA version used by the SB Deep Learning Framework (releases from 1.10.0 to 1.18.1 use CUDA v11.3) or if Nvidia Video driver are correctly installed and its minimum required version satisfied. If it is not the case, update/install the correct driver version.