|
SqueezeBrains SDK 1.18
|
|
SqueezeBrains SDK 1.18
|
Parameters of a model. More...
#include <sb.h>
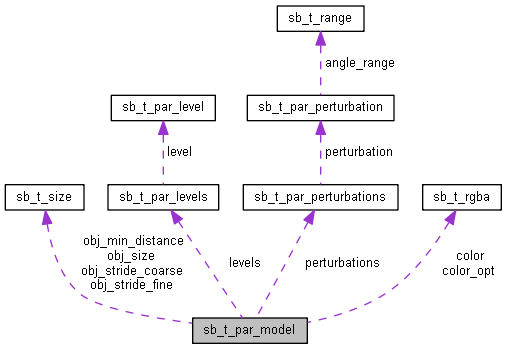
Data Fields | |
| char | name [SB_PAR_STRING_LEN] |
| Model name. More... | |
| char | description [SB_PAR_STRING_LEN] |
| Model description. More... | |
| sb_t_size | obj_size |
| Model size. More... | |
| int | enabled |
| Enabling status of the model. More... | |
| sb_t_par_levels | levels |
| Array of levels parameters for this model. More... | |
| sb_t_par_perturbations | perturbations |
| Perturbations of the samples. More... | |
| sb_t_rgba | color |
| Color of the defects. More... | |
| sb_t_rgba | color_opt |
| Color of the optional defects. More... | |
| sb_t_size | obj_min_distance |
| Minimum distance between two samples. More... | |
| sb_t_size | obj_stride_coarse |
| Coarse search step. More... | |
| sb_t_size | obj_stride_fine |
| Fine search step. More... | |
| int | num_occurrences |
| Number of occurrences of the model that the function sb_project_get_res should export. More... | |
| float | defect_area_percentage |
| Threshold percentage bad area of the sample to discard it as an occurrence. More... | |
| float | defect_area_threshold |
| Threshold weight value for the bad area of the sample. More... | |
Parameters of a model.
| sb_t_rgba sb_t_par_model::color |
Color of the defects.
The value it is not used by the SB library but only by the SB GUI to draw the defect.
Used only by Surface and Deep Surface projects.
| sb_t_rgba sb_t_par_model::color_opt |
Color of the optional defects.
The value it is not used by the SB library but only by the SB GUI to draw the optional defect.
Used only by Surface and Deep Surface projects.
| float sb_t_par_model::defect_area_percentage |
Threshold percentage bad area of the sample to discard it as an occurrence.
This parameter sets the minimum contiguous bad area to give a "bad" even if the total occurrence weight is positive.
The parameter is expresses as a percentage [0, 1.0] of the total sample area.
The admitted values are [0-1.0f].
Set the parameter to 0 to disable the control. Used only by Retina project.
| float sb_t_par_model::defect_area_threshold |
Threshold weight value for the bad area of the sample.
This parameter sets the threshold above which to consider a pixel as a "bad" value.
The admitted values are [-1.0f-1.0f].
Used only by Retina project.
| char sb_t_par_model::description[SB_PAR_STRING_LEN] |
| int sb_t_par_model::enabled |
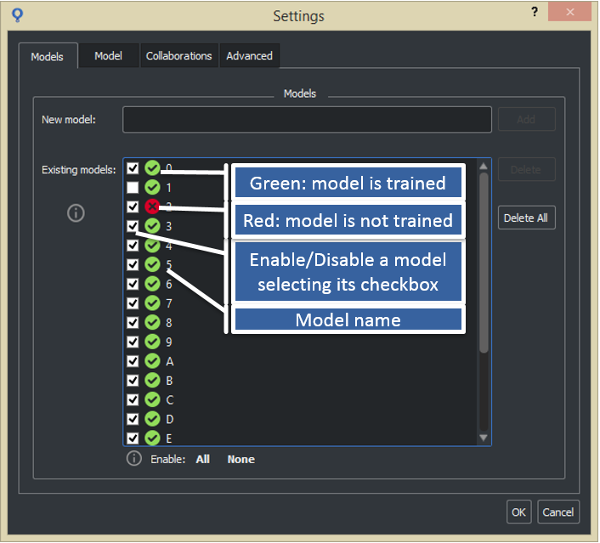
Enabling status of the model.
You can enable/disable each model independently, both when you perform the training (only for Retina and Surface projects) and when you perform the analysis.
In the example Enable/disable a model in a project you can see how to enable/disable a model of a project. The possible values are:
| sb_t_par_levels sb_t_par_model::levels |
Array of levels parameters for this model.
Defines the levels properties:
| char sb_t_par_model::name[SB_PAR_STRING_LEN] |
| int sb_t_par_model::num_occurrences |
Number of occurrences of the model that the function sb_project_get_res should export.
The possibile values of the parameter are the following:
| Value | Description |
|---|---|
| -1 | All occurrences with positive weight and, if exist, the first negative are exported. |
| 0 | All occurrences with positive weight are exported |
| >0 | num_occurrences starting from those with greater weight are exported, regardless of whether the weight is positive or negative. Of course, less than num_occurrences samples may be exported |
Used only by Retina project.
The value must be greater equal than
| sb_t_size sb_t_par_model::obj_min_distance |
Minimum distance between two samples.
The parameter allows you to set the minimum distance between two samples. In the event that two or more samples are closer, the sb_project_detection function chooses the one with the greatest weight and eliminates the others.
You can set the minimum distance in x and y separately.
The parameter is used differently by the sb_svl_run and sb_project_detection functions. See Different results in SVL and Test for more information.
The values width and height represent, respectively, the dimensions of the horizontal and vertical axes of an ellipse centered in the center of the sample. The ellipse defines a buffer zone in which the ellipse of no other sample must enter. If this condition is met then the sample is considered isolated, otherwise, the sample is considered close to other samples. The function sb_samples_distance, to find out if two samples are close or not, checks the intersections between their respective ellipses: if the intersection is zero, the samples are distant, otherwise the samples are considered close. The following image shows samples 1 and sample 2 of two different models in two conditions: on the left the samples are distant and the ellipses do not intersect, while on the right the ellipses intersect so as to consider the samples close.
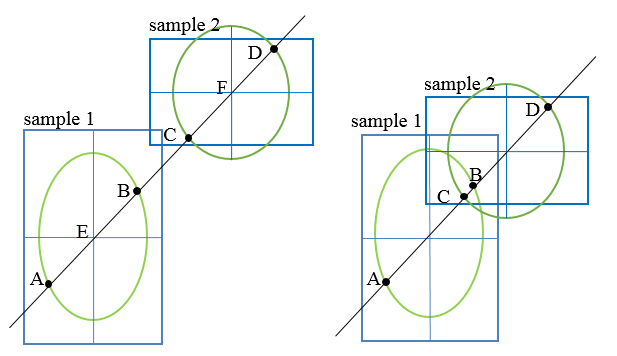
The sb_samples_distance function also takes into account the scale of the sample: the width and height are multiplied by the scale factor of the sample.
The value must be greater equal than SB_PAR_RETINA_OBJ_DISTANCE_MIN and sb_t_par_model::obj_stride_coarse.
Used only by Retina and Surface projects.
| sb_t_size sb_t_par_model::obj_size |
Model size.
Width and height, in pixel, of the rectangular window of the model.
Here are some rules for setting the model size correctly:
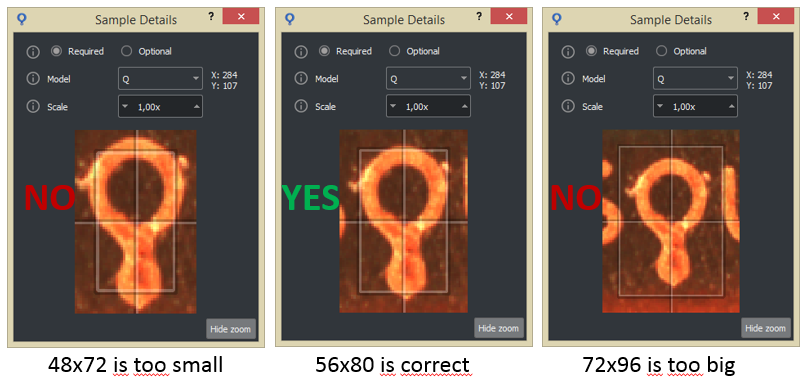
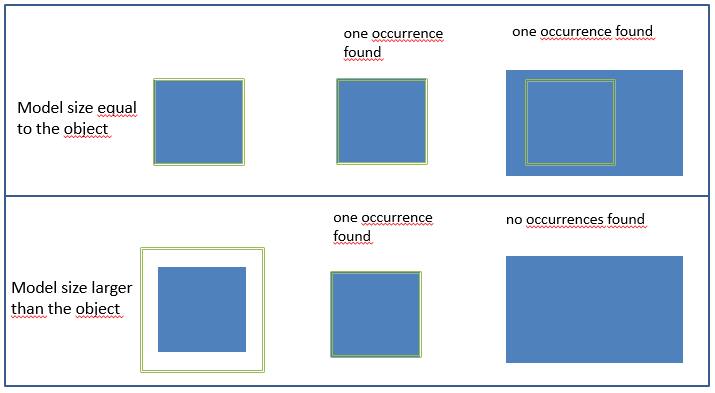
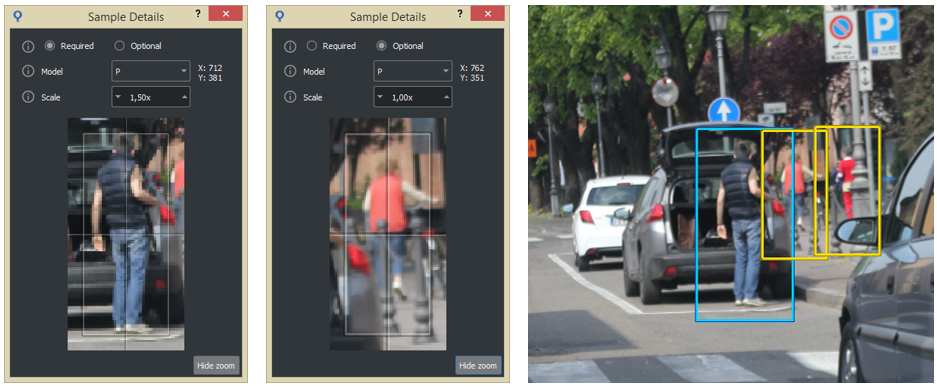
Image with higher resolution
It may happen that the images have a higher resolution than necessary so that the objects are too large in size, incompatible with the needs of classification. In this case we recommend creating the model with the correct size for the classifier (i.e. smaller) and then adding all the samples with a scale factor (greater than 1) in order to thicken the occurrences on the images. This has two benefits:
If the samples vary in size but are contained (variability <25%), we recommend choosing a medium scale factor and using it for all the samples. The classifier handles such small scale variations very well. Using more than one scale would unnecessarily increase calculation times.
Dimension vs Classifier
One must be careful not to increase the size of the model too much for two reasons:
In any case the model does not categorize the data correctly, because of too many details and noise. An indicative maximum size limit of the model is 256x256 pixels. If you are passing it ask yourself if it is really necessary and maybe it is not better to reduce the size and increase the scale factor of the samples.
Used only by Retina and Surface projects.
| sb_t_size sb_t_par_model::obj_stride_coarse |
Coarse search step.
Coarse scan step of the model window on the image.
The parameter has a big impact on the analysis time, the lower the value the greater the analysis time. But the higher the value the greater the probability of having FALSE NEGATIVE samples.
A good rule of thumb for setting the value is: the larger the model size, the larger the parameter value can be.
This value must be greater or equal than sb_t_par_model.obj_stride_fine.
The admitted values are powers of 2, in the range from SB_PAR_RETINA_OBJ_STRIDE_COARSE_MIN to SB_PAR_RETINA_OBJ_STRIDE_COARSE_MAX pixels.
Used only by Retina and Surface projects.
| sb_t_size sb_t_par_model::obj_stride_fine |
Fine search step.
Fine scan step of the model window on the image.
The parameter has a big impact on the analysis time, the lower the value the greater the analysis time. But the higher the value the greater the probability of having FALSE NEGATIVE samples.
A good rule of thumb for setting the value is: the larger the model size, the larger the parameter value can be.
This value must be less or equal than sb_t_par_model.obj_stride_coarse.
The permitted values are between SB_PAR_RETINA_OBJ_STRIDE_FINE_MIN and SB_PAR_RETINA_OBJ_STRIDE_FINE_MAX, but the admitted values are only 1,2,4,8.
Used only by Retina project.
| sb_t_par_perturbations sb_t_par_model::perturbations |
Perturbations of the samples.